
Redis / Spring batch / multi thread / DB / Spring DI 이슈를 모두 겪은 혼란의 ‘주문한 매장’ 기능 개발기
-
지금부터 약 한달 전, 스토어 리스트에서 이전에 주문했던 매장에 ‘주문한 매장’ 표시를 추가해주는 피쳐를 개발하게 되었다.
혼돈의 개발 과정을 겪고 배우게 된 게 많아서 포스트를 작성해야 겠다고 마음 먹었지만, 미루고 미루다가 이제서야 작성한다.
사실 더 미룰 뻔 했지만, 사수와의 DM 내용이 곧 삭제될 것 같아서(슬랙 내용이 한달 뒤에 강제 삭제된다ㅠ) 급하게 쓴다..
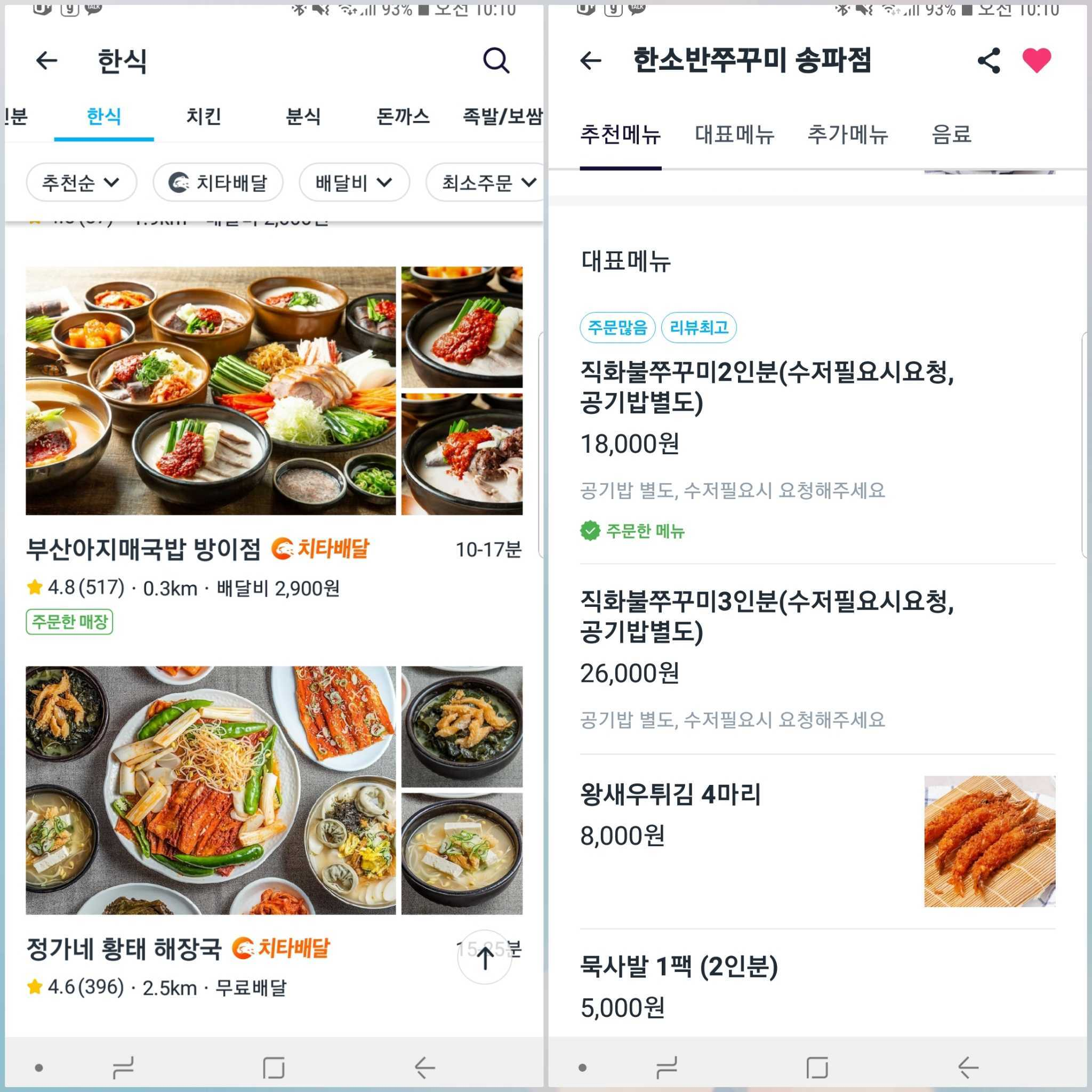
요구사항 (초기)
-
회원 별 주문한 매장, 메뉴에 대해서 스토어 리스트, 스토어 상세 페이지에서 뱃지로 표시해야 한다.
-
주문 후 취소한 경우,
주문한 매장, 메뉴뱃지가 표시되지 않아야 한다.- 단, 2번 이상 주문했는데 한 번만 취소한 경우에는
주문한 매장, 메뉴가 표시되어야 한다.
- 단, 2번 이상 주문했는데 한 번만 취소한 경우에는
-
주문 후 일부 메뉴만 부분 취소한 경우, 부분 취소한 메뉴는
주문한 메뉴뱃지가 표시되지 않아야 한다.- 이것도 취소와 마찬가지로 해당 메뉴를 여러번 주문했는데 한번만 부분 취소한 경우에는
주문한 메뉴가 표시되어야 한다. - 해당 메뉴를 2개 이상 주문했는데 1개만 부분 취소할 경우에도
주문한 메뉴표시가 되어야한다.
- 이것도 취소와 마찬가지로 해당 메뉴를 여러번 주문했는데 한번만 부분 취소한 경우에는
-
고객 주문 정보를 실시간으로 업데이트해서 배달 완료까지 되었을 때 바로
주문한 매장, 메뉴가 표시되어야 한다.
초기 설계
- 회원 별로 주문한 매장, 메뉴 정보를 DB와 Redis 캐시에 저장한다.
- DB : 주문 취소나 부분 취소가 발생했을 때 같은 매장이나 메뉴에 대해 이번 주문 외에 다른 주문 이력이 있는지 확인하기 위함
- 즉, 회원 별 주문한 매장, 메뉴의 주문 횟수 카운트 용
- Cache : 스토어 리스트, 스토어 상세 페이지 진입 시 해당 회원이 주문한 매장, 메뉴가 있는지 조회하기 위함
- DB : 주문 취소나 부분 취소가 발생했을 때 같은 매장이나 메뉴에 대해 이번 주문 외에 다른 주문 이력이 있는지 확인하기 위함
- 실시간으로 주문들의 배달 완료 이벤트, 주문 취소, 부분 취소 이벤트를 받아서 DB와 캐시를 업데이트한다.
Backfill 배치 구현
- 기존 주문 정보를 DB와 캐시에 저장하기 위한 Backfill 배치를 구현해야 했다.
초기 구현
- 주문을 관리하는 서비스에 일정 기간 내의 주문 정보를 요청해 가져와 DB와 캐시에 insert 한다.
문제점 및 해결 과정
주문 서비스로의 주문 정보 조회 요청 delay
- 배치 parameter로
startDate,endDate를 입력받도록 구현했는데, 파라미터로 사용자가 기간을 얼마나 길게 정해 입력할지 알 수 없다.- 기간이 늘어날수록 그 기간 내의 주문 정보 개수가 늘어나기 때문에 조회 시에 DB 부하가 커져 timeout이 발생하게 된다.
- 주문 정보가 담겨있는 DB select query에 걸리는 delay
- 주문 서비스에 api 요청을 보내고 응답을 받아오는데 걸리는 delay
- 최대 2일 단위로 기간을 나눠 주문 서비스에 요청을 보내도록 수정했다.
- 기간을 나눠 요청을 보내는 반복문 안에
Thread.sleep(1000)으로 1초씩 텀을 주도록 했다. - 주문 서비스도 계속해서 api 요청을 받아 처리하려면 부담이 있을거라 예상해서이다.
- 기간을 나눠 요청을 보내는 반복문 안에
- 기간이 늘어날수록 그 기간 내의 주문 정보 개수가 늘어나기 때문에 조회 시에 DB 부하가 커져 timeout이 발생하게 된다.
너무 긴 배치 실행 완료 예상 시간
-
dev 환경에서 테스트로 돌려본 배치의 실행 시간을 기준으로 현재 운영에 있는 모든 주문 정보를 backfill 하는데 걸리는 시간을 계산해봤을 때, 약 1년정도가 나왔다(!)
-
배치 실행 시간의 큰 부분을 차지하는 두 개가 있는데, 주문 서비스에서 주문 정보를 받아오는 시간 + 받아온 주문 정보를 DB에 저장하는 시간 이 그것이다.

-
또, 주문 서비스에 요청을 한번 보낼 때마다 1초씩 쉬도록 텀을 주어서 그 시간도 꽤나 영향을 주었다.
(요청 받아오는 시간의 3분의 1이나 됐기 때문에..)

- 요청 한 번에 sleep 1초는 너무 긴 느낌이어서 요청 5번에 sleep 0.5초로 수정했다.
- 한번에 가져오는 개수 =
pageSizepageSize가 300 일 때 응답시간이 3초였고,pageSize가 클수록 주문 서비스에 요청 보내는 횟수 자체가 적어지기 때문에 커질수록 좋다.- 주문 서비스에서 한번의 db transaction으로 더 많은 데이터를 조회하고, 한 번의 api 요청으로 더 많은 데이터를 가져올 수 있기 때문에 요청 횟수가 적어지면 db connection 시간이나 api 요청 시간을 절약할 수 있다.
- 그러나 api 응답 시간이 5초 이상이면 api gateway 자체에서 timeout으로 끊어버리기 때문에 적당히 300으로 설정해 돌리기로 했다.
- 주문 서비스에서 주문 정보 200개를 한번에 받아오고, 싱글 스레드로 row 하나씩 insert하고 있었다.
orders.parallelStream()으로 multi thread로 동시에 여러 row를 insert하도록 수정했다.
중요한 건 아닌데 한줌 주문량이라는 말이 넘 웃겨서ㅋㅋㅋ
-
결론
- 위와 같이 여러번의 수정을 거친 뒤 약 일주일만에 backfill 배치를 완료할 수 있었다.
첫번째 배포 - message consumer 이슈
-
첫번째 배포를 하고 다음날, 운영 DB 데이터를 확인해봤을 때 전날 주문 개수가 현저하게 적었다.
- 즉, 배달 완료 event를 받아서 DB와 캐시에 저장하는 로직에 뭔가 이슈가 발생해서 제대로 수행되지 않았다.
- 확인해본 결과 운영에서는 application이 실행되고 종료될 때마다 consumer를 start/stop 해주는 internal webhook api가 필요한데, 그걸 설정을 안해줘서 consumer가 start되지 않아 이벤트를 컨슘하지 못했던 것이다.
- 일부 들어간 153개의 데이터는 배포 중 canary 단계에서 잠깐 consumer가 켜졌을 때 배달완료 이벤트를 consume하여 처리한 것으로 보인다.
- start/stop webhook api를 추가해준 뒤에는 정상적으로 컨슘할 수 있었으나,…또 다른 문제가 발생했다.
- (api 추가 후 authroization exclude 패턴에 추가하지 않아서 다시 수정하고 배포한거는 비밀이다.)
두번째 배포 - consumer rebalance 이슈
-
consumer start/stop api 추가 후 다시 운영 배포를 진행했다.
-
이번에는 error 로그가 다수 발생했다.
운영 서비스에서 에러가 발생하면 alert 채널에 알림이 계속해서 오는데 그 알림에 모든 개발자들이 태그되어 있기 때문에 모든 개발자들에게 알림이 간다. (상위 매니저 포함)
내가 운영 배포중에 해당 서비스 에러 alert이 울리면 TL과 팀 매니저 등 다수의 관심을 받을 수 있어 정말 울고싶은 기분이 든다…
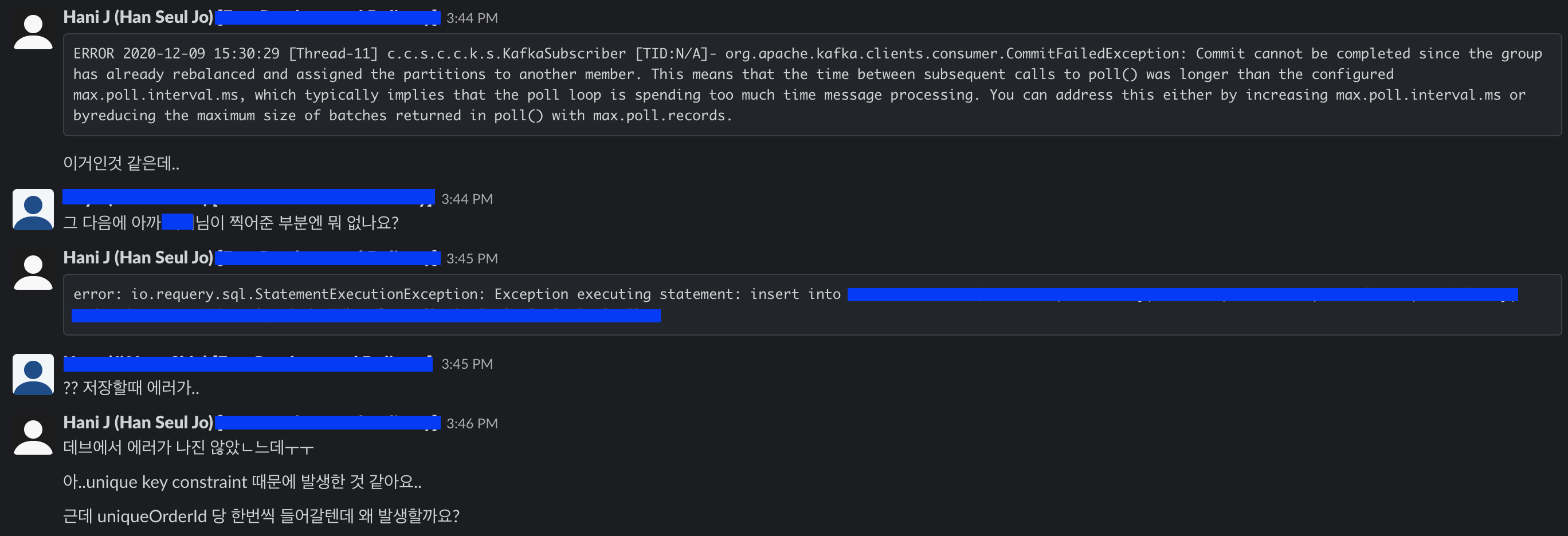
ERROR 2020-12-09 15:30:29 [Thread-11] c.c.s.c.c.k.s.KafkaSubscriber [TID:N/A]- org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing max.poll.interval.ms or byreducing the maximum size of batches returned in poll() with max.poll.records.
- 위의 에러는 간헐적으로 보였고, alert이 발생한 주된 에러는
StatementExecutionException같았다. - backfill 배치를 구현할 때, 날짜 단위로만 설정해서 배치를 실행할 수 있기 때문에 배치를 실행하는 중간에 에러가 발생했을 때 같은 기간의 배치를 다시 실행해야 할 경우가 발생할 수도 있다.
- 같은 주문건에 대해 중복으로 저장하지 않게 하기 위해 주문번호 column에 대해 unique key constraint을 추가했었다.
- 위의
StatementExecutionException은 unique key constraint을 어기는 insert query를 실행하려고 해서 발생한 것이다.- 그런데, 하나의 주문 건에 대해 한번의 배달 완료 이벤트가 발생하는데, 이상하게 같은 주문번호에 대해서 insert query를 여러번 실행하려고 한 로그들이 보였다.
- 그러던 중 위에서 본 kafka의
CommitFailedException이 신경쓰여 더 자세히 찾아봤다.

Rebalance
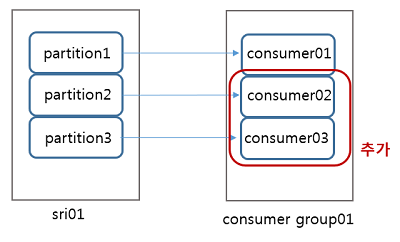
- consumer group 안에서 consumer들은 메시지를 가져오고 있는 topic의 partition에 대해 소유권을 공유하고 있다.
- consumer group은 consumer가 producer의 메시지 생성 속도를 따라가지 못할 때, consumer 확장을 용이하게 하기 위한 기능이다.
- 그 중 한 consumer가 추가되거나 삭제 되었을 때 topic에 대한 소유권이 이동하게 되는데, 이것을 rebalance 라고 한다.
Rebalance가 일어날 수 있는 두가지 케이스
-
producer가 topic에 메시지를 보내는 속도가 증가하여 consumer가 메시지를 가져가 처리하는 속도보다 빨라지게 되면,
- consumer group에 consumer를 추가해서 내부적으로 균형을 맞추도록 한다.
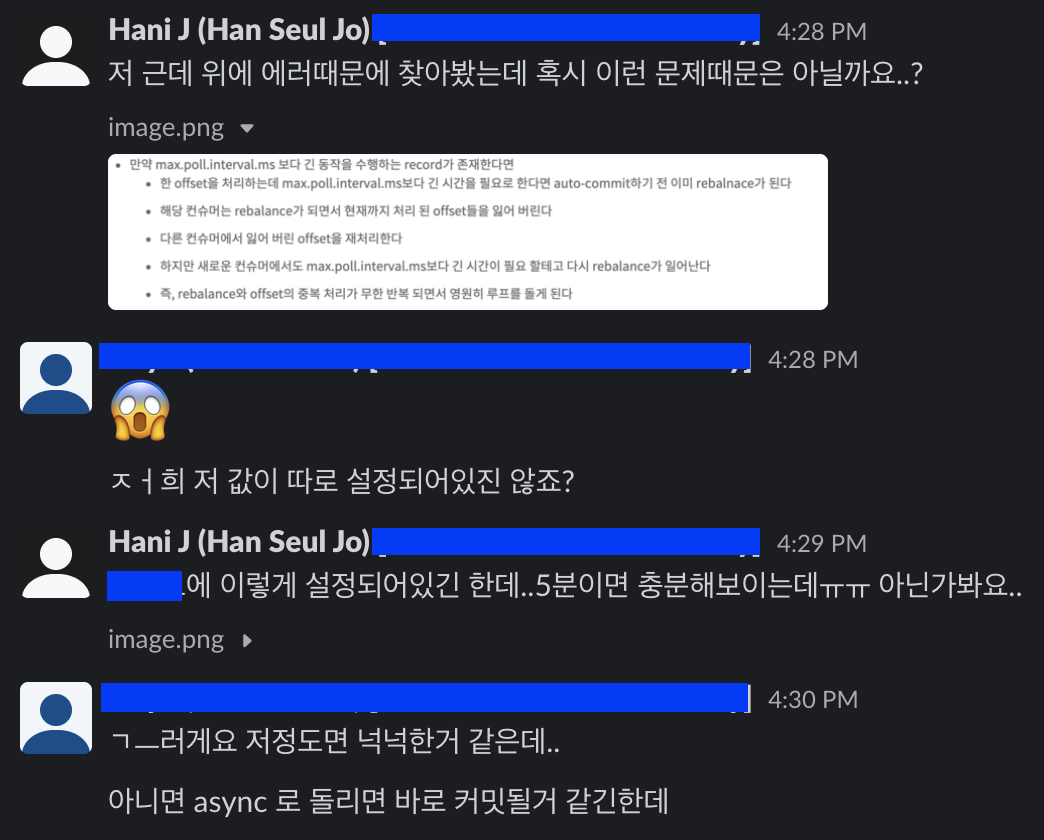
-
max.poll.interval.ms에 설정된 값보다 긴 시간동안 수행되는 메시지가 존재한다면,- 한 offset을 처리하는데
max.poll.interval.ms보다 긴 시간을 필요로 한다면 auto-commit 하기 전에 rebalance가 일어난다.
- 한 offset을 처리하는데
Rebalance가 일어났을 때 메시지가 중복 소비되는 문제 발생
- Rebalance가 일어나는 동안 일시적으로 consumer는 메시지를 가져올 수 없다.
- consumer가 offset을 처리하는 도중에 rebalance가 일어나면 현재까지 처리한 offset을 커밋하지 못하고 잃게 된다.
- rebalance가 일어난 후, 각 consumer는 이전에 처리했던 topic의 partition이 아닌 다른 새로운 partition에 할당된다.
- consumer는 새로 할당된 partition에서 가장 최근에 커밋된 offset을 읽고, 그 다음 offset을 가져와 처리한다.
- 즉, 다른 consumer가 이전에 잃어버린 offset을 재처리하게 된다.
- 하지만, 새로운 consumer에서도 offset을 처리할 시간이 부족해서 다시 rebalance가 일어나게 된다.
- 즉, rebalance와 offset의 중복 처리가 무한 반복되면서 에러가 발생하게 된다.
- 참고
- https://saramin.github.io/2019-09-17-kafka/
- https://dev-punxism.tistory.com/entry/Kafka-Consumer-maxpollintervalms-설정하기
- https://medium.com/11st-pe-techblog/카프카-컨슈머-애플리케이션-배포-전략-4cb2c7550a72
해결방법

- consumer가 단일 스레드로 메시지를 처리하고 있기 때문에 처리 시간이 오래 걸리는 것이라 판단했다.
-
consumer가 메시지를 컨슘해서 처리하는 부분을 async로 처리하도록 Service 클래스에
@Async어노테이션을 추가했다. - async로 수정 후 배포했을 때 더이상 같은 에러는 발생하지 않았다. 그러나, 또 새로운 에러가 무수히 많이 발생되었다…
세번째 배포 - DB Spike 이슈
-
배달완료, 주문 취소, 부분 취소 이벤트를 컨슘하는 비즈니스 로직 부분을 Async로 처리하도록 수정해서 배포를 다시 진행했다.
-
그리고 또 다시 canary 과정에서 많은 alert이 발생했다.
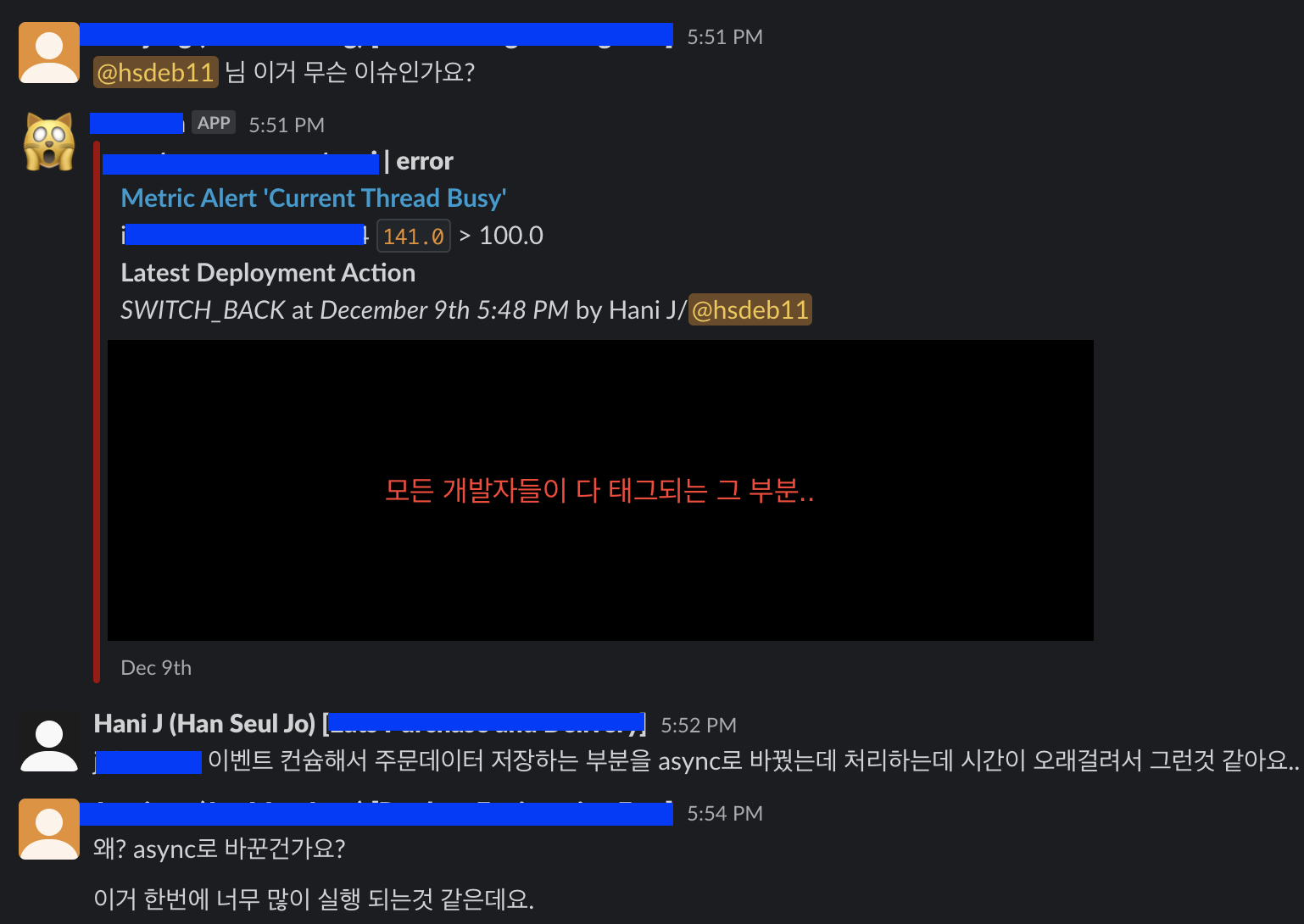
- 수많은 주문 완료, 취소, 부분 취소를 실시간으로 비동기적으로 받아서 DB select, insert 등의 처리까지 하려니 DB CPU에 부담이 간 것이다.
- Thread busy alert이 발생한 것을 확인할 수 있다.
- 수많은 주문 완료, 취소, 부분 취소를 실시간으로 비동기적으로 받아서 DB select, insert 등의 처리까지 하려니 DB CPU에 부담이 간 것이다.
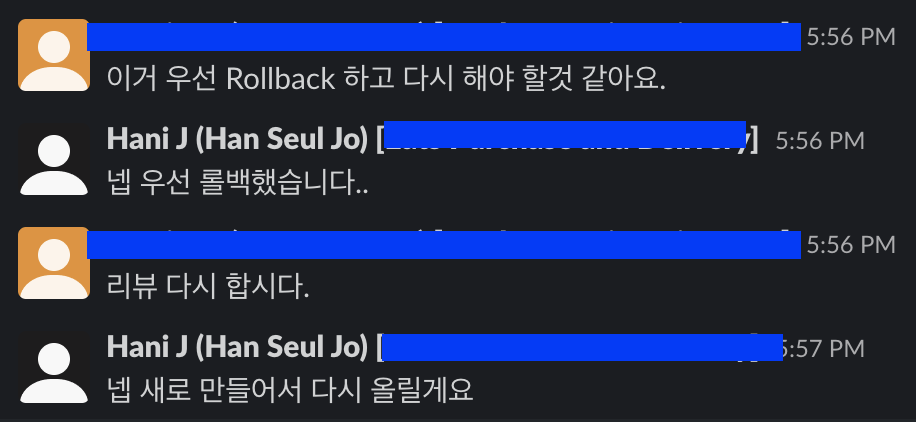
-
원래 보통 dev 환경에서 QA 시작하기 전쯤에 코드 리뷰를 먼저 받는데, 이때는 코드 리뷰를 받은 시점으로부터 많은 부분이 변경되어있긴 했었다.
- 코드 리뷰 받는 시점이 참 애매한것 같다..hotfix로 나가다 보면 리뷰를 제대로 못 받고 나가는 경우가 생길 때도 있으니ㅠ
-
다시 코드 리뷰를 받도록 했다.
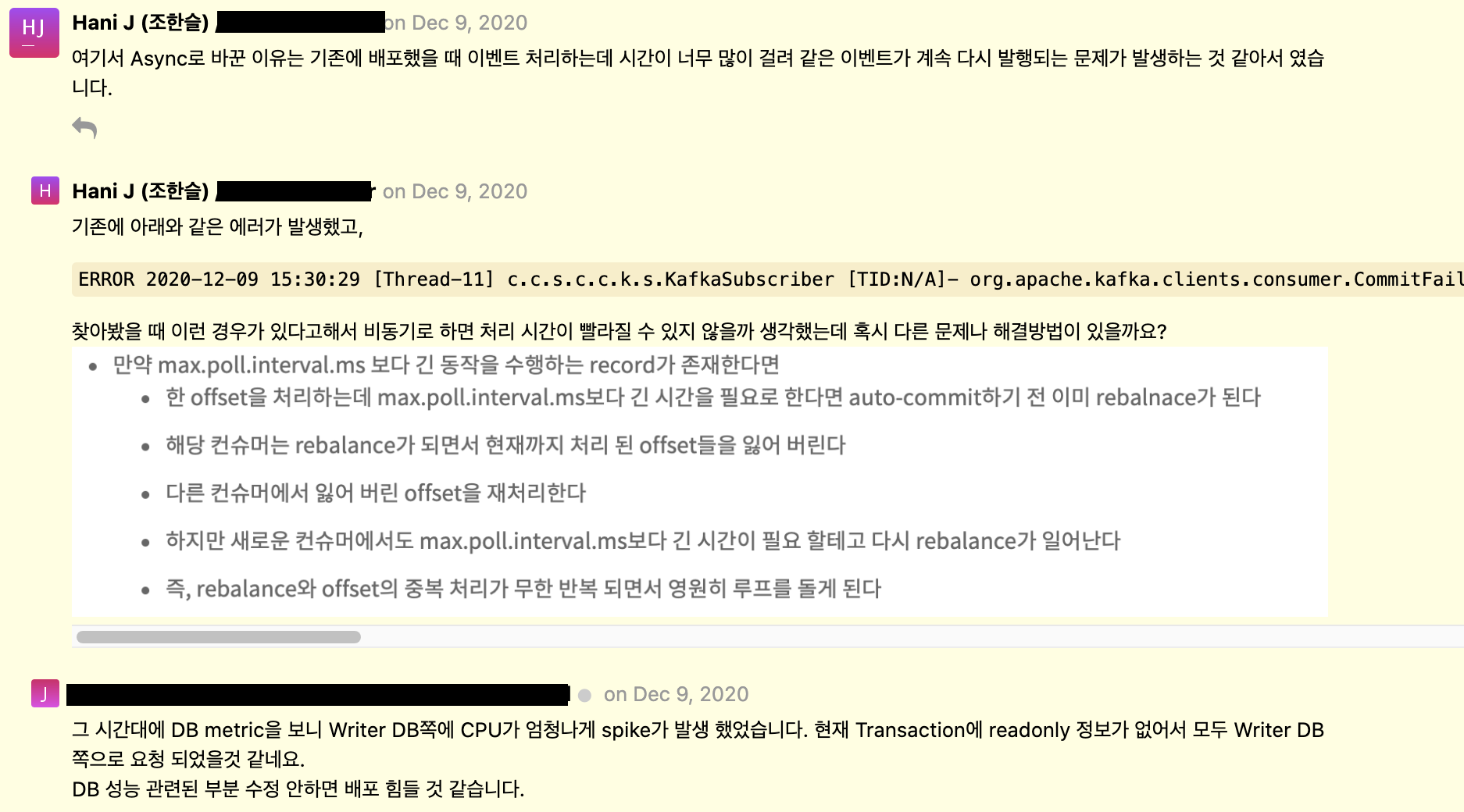
- 다음날 오전에 사수와 TL(위에 리뷰 코멘트 남겨주신 분)과 회의를 한 결과, 실시간으로 주문 이벤트를 받아서 처리하는 것은 성능상 무리가 있다고 판단했다.
- 실시간으로 주문 완료, 취소, 부분취소 이벤트를 받아서 주문한 매장, 메뉴를 표시해주는 기능은 성능 이슈로 없애기로 했다.
- 대신 backfill 배치를 수정해서 daily 배치로 당일 주문건들에 대해 새벽에 cache에 주문 정보를 업데이트할 수 있도록 했다.
- daily 배치로 변경하게 되면서 주문 취소나 부분취소 이벤트를 처리하기가 애매해져 취소된 주문이나 메뉴에 대해서는 따로 처리하지 않기로 했다.
- 주문 취소, 부분취소를 처리하지 않으니 주문한 매장이나 메뉴에 대해서 주문 횟수 카운트를 할 필요가 없어져 DB에 데이터를 넣을 의미가 없어졌다.
- Redis cache에 새로 주문완료된 주문 정보만 계속해서 add하고 캐시에서 바로 조회하면 되기 때문이다.
- 요구사항이 수정된 덕분에 구조가 좀 더 간단해졌다.
- subscriber들과 DB가 필요없어졌고, daily 배치만 구현하면 되었다.
네번째 배포 - RedisTemplate bean DI 이슈
-
변경된 요구사항에 맞춰 구조와 구현을 수정한 뒤 다시 배포를 준비중에 QA분에게서 DM이 왔다.
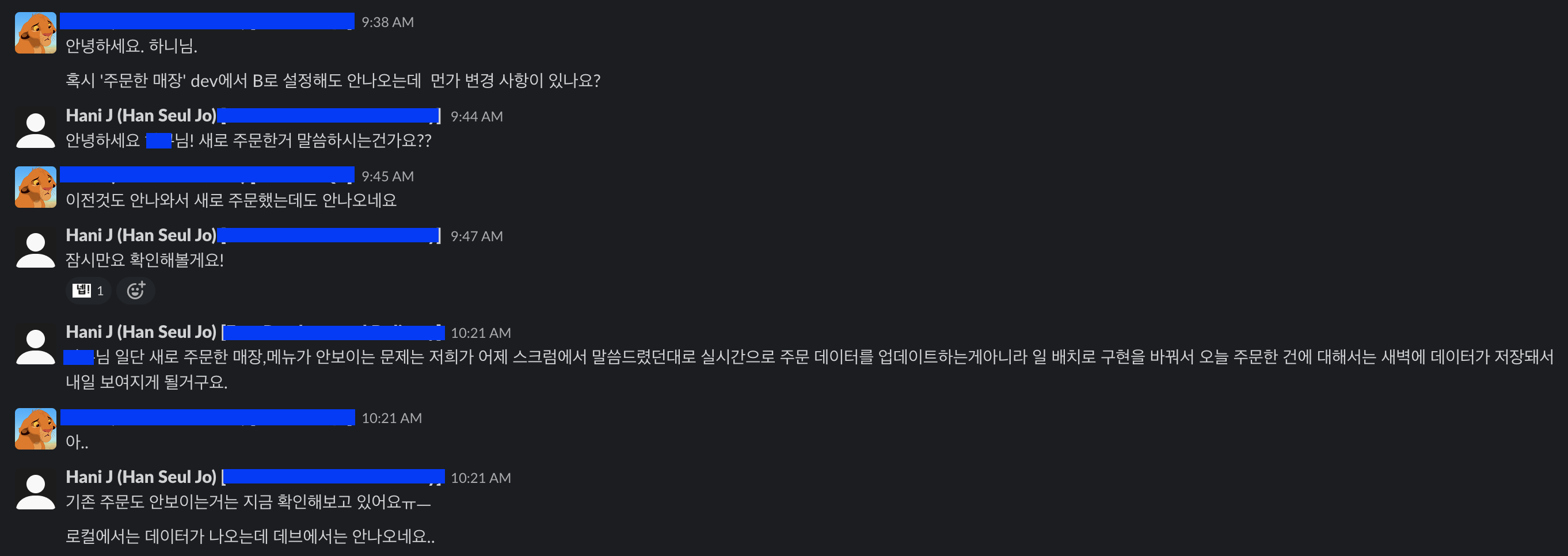
- 이상하게 로컬에서 develop 프로필로 application을 실행했을 때는 데이터가 잘 나왔는데 dev 환경에서 api를 요청했을 때는 데이터가 아예 빈 값으로 나왔다.
-
레디스를 확인해봤을 때 데이터가 잘 들어있는데도 조회가 되지 않았다.
-
여러번 재배포를 진행해본 결과, 특정 피쳐브랜치가 머지되었을 때 레디스가 다른 host를 바라보게 되는 것 같았다.
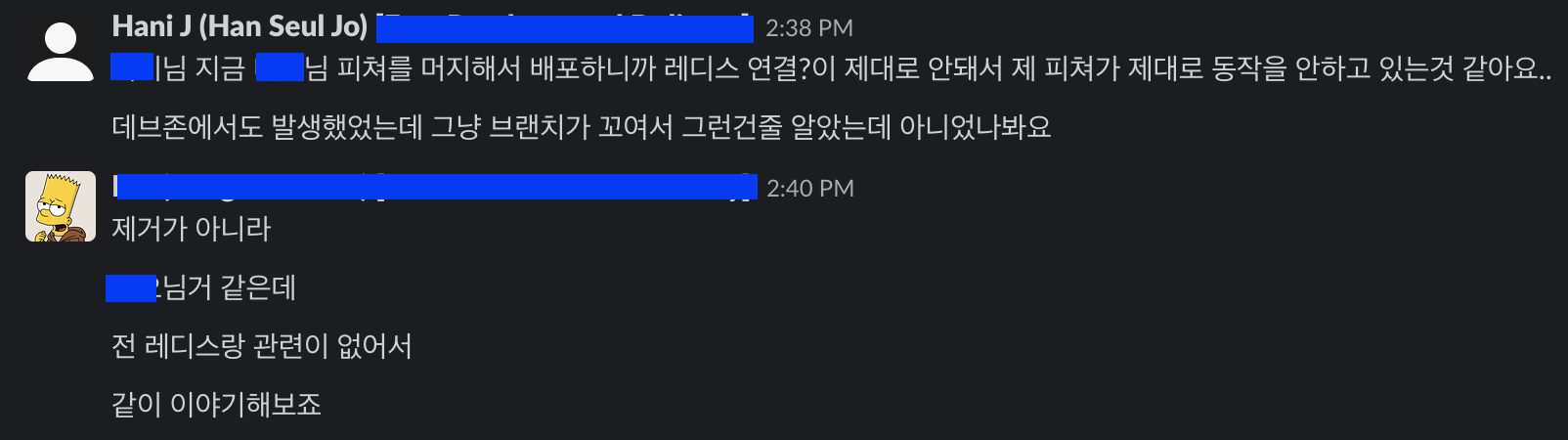
- 저 말 자체가 책임을 미루는 느낌이라 내가 쓰면서도 너무 싫었지만 사실이라..일단 해결을 위해서 여쭤봤다.
- 이렇게 또 논의가 시작됐다. 이쯤 되니 이거 무사히 끝나긴 하는걸까 의심스러워졌다.
- 저 말 자체가 책임을 미루는 느낌이라 내가 쓰면서도 너무 싫었지만 사실이라..일단 해결을 위해서 여쭤봤다.
-
분명 redis 연결을 위한
RedisConnectionFactory빈과RedisTemplate빈은 각각 하나씩 밖에 없는데, 왜 다른 redis host에 연결이 된건지 알 수 없었다.-
서치해본 결과
spring-boot-starter-data-redisdependency를 추가했을 때 localhost로 연결하는RedisConnectionFactory빈과RedisTemplate빈이 Auto-configuration으로 존재한다고 한다.(참고 : https://tech.asimio.net/2017/10/17/Disabling-Redis-Autoconfiguration-in-Spring-Boot-applications.html)
-
위 참고 페이지에서 나온 방법대로 auto-configuration을 disable 하는 방법도 사용해보았으나 역시 제대로 되지 않았다.
-
그러나 기본 auto-configuration으로 인한 localhost가 아니더라도 뭔가 다른 host에 연결되고 있다는 확신이 들었다.
-
문제 해결 - bean @Qualifier
-
기존에
RedisConnectionFactory빈과RedisTemplate빈을 선언할 때 name 속성을 따로 지정하지 않았었는데, name 속성 값을 설정하고,@Qualifier어노테이션으로 custom bean을 지정해주니 내가 원하는 redis host에 연결되어 데이터가 잘 나오게 되었다.-
처음에는 단순히
RedisTemplate빈의 name을 “redisTemplate” 으로 하고, 빈 주입받는 곳에서@Qualifier를 넣으니 다음과 같은 에러(?)가 발생했다.
RedisTemplate빈을 선언하는 곳에서도<String, String>타입으로 잘 선언했는데도 타입이 맞지 않는다는 오류였다.- 뭔가 이상함을 감지했고,
@Qualifier의 implementation을 따라가보니 엉뚱한 빈 선언부를 만날 수 있었다.
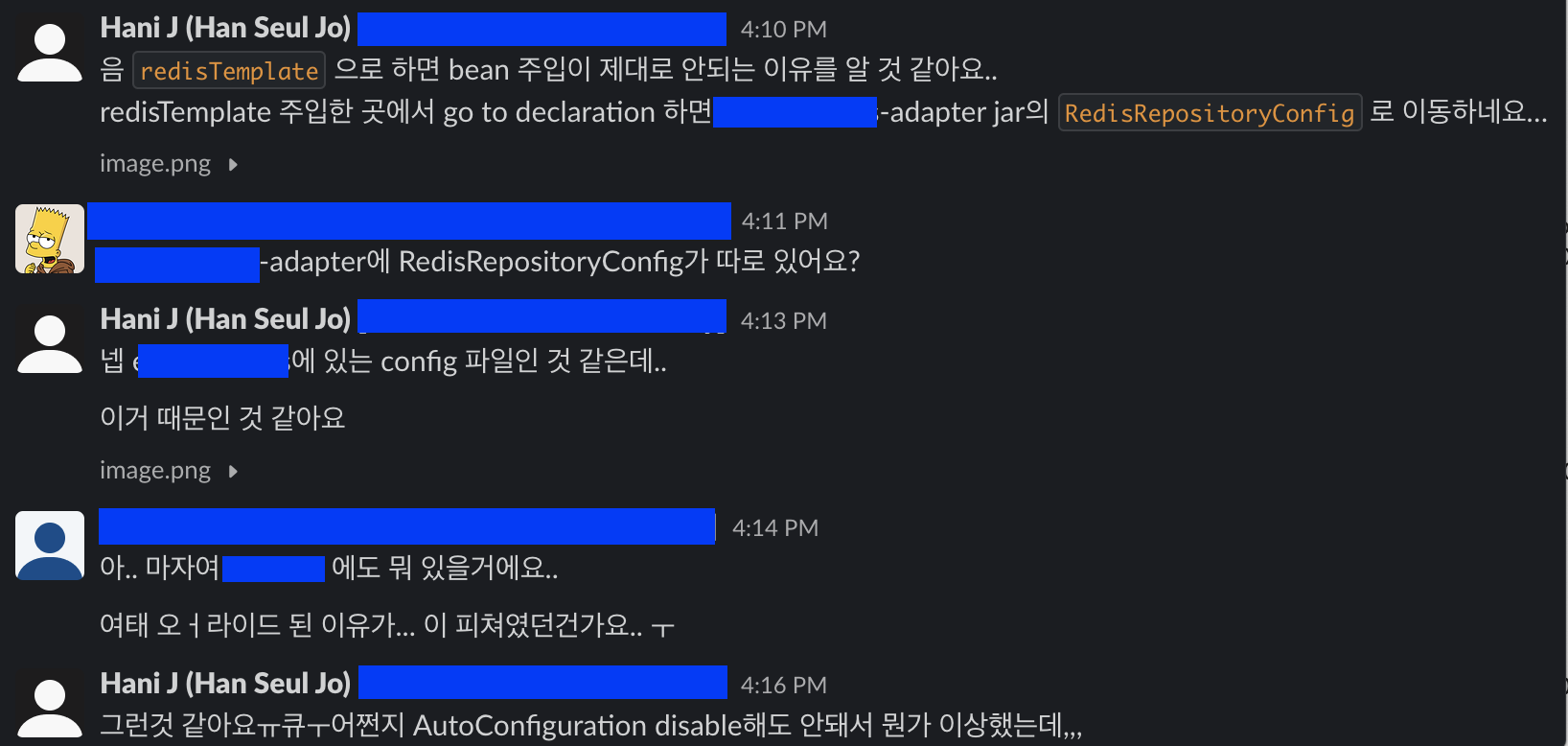
-
알고보니 다른 서비스의 adapter 라이브러리가 포함되면서 해당 jar의
RedisTemplate빈과 충돌이 일어났던 것이다. -
라이브러리 jar와 현재 서비스의
RedisConnectionFactory빈과RedisTemplate빈이 두 곳 다 name이 따로 설정되어 있지 않아서 jar 파일의redisTemplate빈이 먼저 주입된 것이다.
-
-
문제의 원인을 파악하고나서 다시 해당 라이브러리를 추가하고 계신 개발자님과 4인 미팅(2인에서 3인,,4인까지 늘어났다)을 한 뒤 라이브러리 쪽 config를 수정하기로 하고 이 이슈도 마무리되었다.
회고
- 지금 이 포스트를 작성하면서 기간을 보니 이 기능에만 약 3주정도 시간을 할애한 것 같다.
- 이렇게 길고 이슈도 많았던 피쳐 개발은 처음이었어서 중간부터 너무 힘들었지만, 배운 점도 많았고 같은 팀 동료분들이 너무 많이 도와주시고 조언도 주셔서ㅠㅡㅠ 감사하게도 잘 마무리했다.
- 사실 하나하나 이슈가 발생하게 된 원인과 베이스 개념들을 세세하게 정리하고 싶었는데, 너무 이슈도 많았고 내용도 방대해질 것 같아서 간단하게만 정리했다.
- 다음에 기회가 되면 message broker 쪽은 좀 더 자세히 공부해보고 싶다.
- spring DI도.. 무슨 기준으로 빈이 먼저 주입되는건지 알다가도 모르겠다.
- 오늘 마침 이 기능의 AB test가 종료되었는데, 테스트에서 져서 이 기능은 이제 더이상 세상의 빛을 볼 수 없게 됐다^.ㅠ
- 서비스의 성능 면으로 보면 다행인 일인데 마음이 조금 아프다.
- 그리고 RedisTemplate 빈 이슈때 팀원분이 로컬에서 디버깅모드로 실행해서 레디스 연결이 다른 host로 되고 있는거를 보여주셨는데, 사실 반이상을 따라가지 못했던 것 같다.
- 디버깅하는 방법도 좀 많이 익혀야 할 것 같다.