
BOOK 3 - 자바 ORM 표준 JPA 프로그래밍(15)
트랜잭션과 락, 2차 캐시
트랜잭션과 락
트랜잭션과 격리 수준
- 트랜잭션은 ACID를 보장해야 한다.
- Atomicity (원자성) : 트랜잭션 내에서 실행한 작업들은 하나로 묶여 모두 성공하거나 모두 실패해야 한다.
- Consistency (일관성) : 모든 트랜잭션은 일관성 있는 데이터베이스 상태를 유지해야 한다.
- 예를 들어, 데이터베이스에서 정한 무결성 제약 조건을 항상 만족해야 한다.
- Isolation (격리성) : 각 트랜잭션은 격리되어 동시에 실행되는 트랜잭션들이 서로 영향을 미치지 않아야 한다.
- 격리성은 동시성과 관련된 성능 이슈로 인해 격리 수준을 선택할 수 있다.
- Durability (지속성) : 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 한다.
- 트랜잭션 간에 격리성을 완벽히 보장하려면 모든 트랜잭션을 거의 차례대로 실행해야 한다.
- 이렇게 하면 동시성 처리 성능이 매우 나빠진다.
- 이런 문제로 인해 격리 수준을 4단계로 나누었다.
트랜잭션 격리 수준
- READ UNCOMMITED : 커밋하지 않은 데이터를 읽을 수 있다.
- READ COMMITED : 커밋한 데이터만 읽을 수 있다.
- REPEATABLE READ : 한 번 조회한 데이터를 반복해서 조회해도 같은 데이터가 조회된다.
- SERIALIZABLE : 가장 엄격한 트랜잭션 격리수준이다.
- 격리 수준이 낮을수록 동시성은 증가하지만 격리 수준에 따른 다양한 문제가 발생한다.
| 격리 수준 | DIRTY READ | NON-REPEATABLE READ | PHANTOM READ |
|---|---|---|---|
| READ UNCOMMITED | O | O | O |
| READ COMMITED | O | O | |
| REPEATABLE READ | O | ||
| SERIALIZABLE |
- DIRTY READ
- 예를 들어, 트랜잭션1이 데이터를 수정하고 있는데 커밋하지 않아도 트랜잭션2가 수정 중인 데이터를 조회할 수 있다.
- 트랜잭션2가 DIRTY READ한 데이터를 사용하는데 트랜잭션1이 롤백되면 데이터 정합성에 심각한 문제가 발생한다.
- NON-REPEATABLE READ
- 예를 들어, 트랜잭션1이 회원 A를 조회하는 중간에 트랜잭션2가 회원 A를 수정하고 커밋하면 트랜잭션1이 다시 회원 A를 조회했을 때 수정된 데이터가 조회된다.
- 반복해서 같은 데이터를 읽을 수 없는 상태를 의미한다.
- PHANTOM READ
- 예를 들어, 트랜잭션1이 10살 이하의 회원을 조회하는 중간에 트랜잭션2가 5살 회원을 추가하고 커밋하면 트랜잭션 1이 다시 10살 이하의 회원을 조회했을 때 회원 하나가 추가된 상태로 조회된다.
- 반복 조회 시 결과 집합이 달라지는 것을 의미한다.
어플리케이션은 대부분 동시성 처리가 중요하므로 데이터베이스들은 보통 READ COMMITED 격리 수준을 기본으로 사용한다.
일부 중요한 비즈니스 로직에 더 높은 격리 수준이 필요하면 데이터베이스 트랜잭션이 제공하는 Lock 기능을 사용하면 된다.
낙관적 락과 비관적 락 기초
- JPA의 영속성 컨텍스트를 적절히 활용하면 데이터베이스 트랜잭션이
READ COMMITED격리 수준이어도 어플리케이션 레벨에서REPEATABLE READ가 가능하다. - JPA는 데이터베이스 트랜잭션 격리 수준을
READ COMMITED정도로 가정한다.- 일부 로직에 더 높은 격리 수준이 필요하면 낙관적 락과 비관적 락 중 하나를 사용하면 된다.
- 낙관적 락은 트랜잭션 대부분은 충돌이 발생하지 않는다고 낙관적으로 가정하는 방법이다.
- JPA가 제공하는 버전 관리 기능을 사용한다.
- 즉, 어플리케이션이 제공하는 락이다.
- 트랜잭션을 커밋하기 전까지는 트랜잭션의 충돌을 알 수 없다.
- JPA가 제공하는 버전 관리 기능을 사용한다.
- 비관적 락은 트랜잭션의 충돌이 발생한다고 가정하고 우선 락을 걸고보는 방법이다.
- 데이터베이스가 제공하는 락 기능을 사용한다.
- 추가적으로, 데이터베이스 트랜잭션 범위를 넘어서는 두 번의 갱신 분실 문제(second lost updates problem)가 있다.
- 예를 들어, 사용자 A와 B가 동시에 같은 공지사항의 제목을 수정한다고 하자.
- 사용자 A가 먼저 수정을 완료하고, 잠시 후에 사용자 B가 수정을 완료하면 결과적으로 먼저 완료한 사용자 A의 수정사항은 사라지고 나중에 완료한 사용자 B의 수정사항만 남게된다.
- 이 문제는 데이터베이스 트랜잭션 범위를 넘어서므로 다음 3가지 방법으로 해결할 수 있다.
- 마지막 커밋만 인정하기
- 최초 커밋만 인정하기
- 충돌하는 갱신 내용 병합하기
- 예를 들어, 사용자 A와 B가 동시에 같은 공지사항의 제목을 수정한다고 하자.
@Version
- JPA가 제공하는 낙관적 락을 사용하려면
@Version어노테이션을 사용해서 버전 관리 기능을 추가해야 한다. @Version적용 가능 타입은 다음과 같다.LongIntegerShortTimestamp
@Entity
public class Board {
@Id
private String id;
private String title;
@Version
private Integer version;
}
- 엔티티에 버전 관리용 필드를 하나 추가하고
@Version어노테이션을 지정해준다. - 엔티티를 수정할 때마다 버전이 하나씩 자동으로 증가한다.
- 엔티티를 수정할 때 조회 시점의 버전과 수정 시점의 버전이 다르면 예외가 발생한다.
// 트랜잭션1에서 Board 조회 (version = 1)
Board board = em.find(Board.class, id);
// 트랜잭션2에서 해당 board의 title을 'title3'로 수정하고 커밋해서 version = 2로 증가
board.setTitle("title2");
save(board);
tx.commit(); // 예외 발생 (데이터베이스 version=2, 엔티티 version=1)
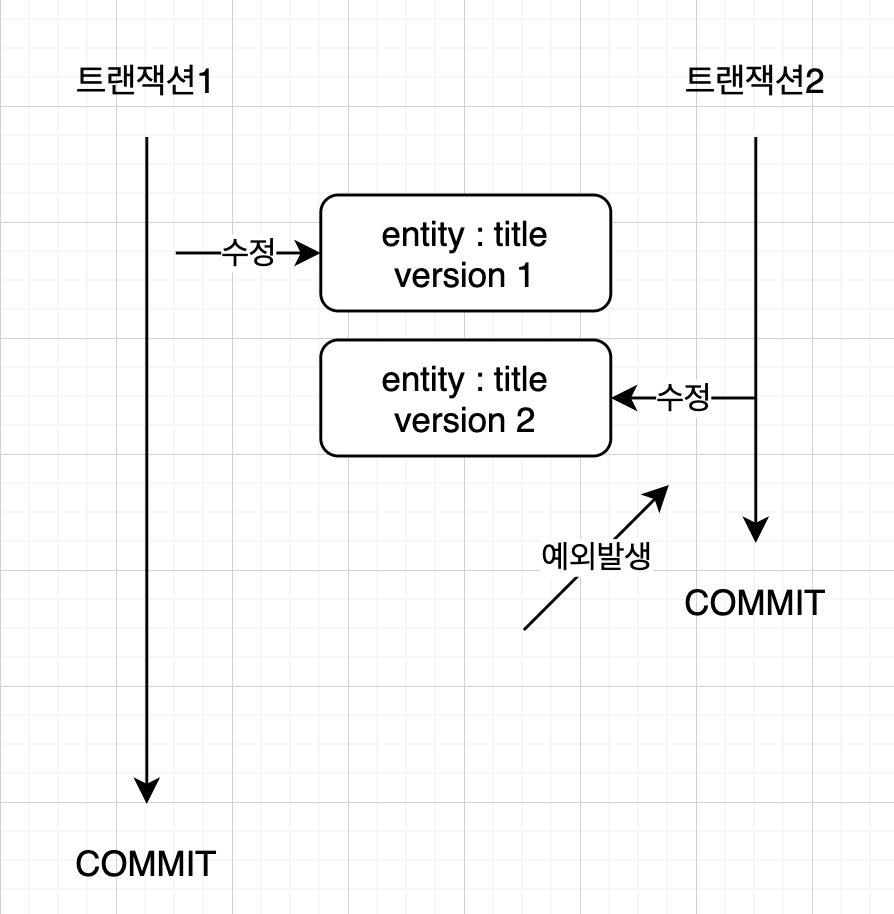
- 버전 정보를 사용하면 최초 커밋만 인정하기가 적용된다.
- 트랜잭션1이 트랜잭션을 커밋하는 순간 엔티티를 조회할 때 버전과 데이터베이스의 현재 버전이 다르므로 예외가 발생한다.
- 따라서 트랜잭션1이 수정하려고 했던
title2는 무시되고, 트랜잭션2가 수정한title3가 인정된다.
버전 정보 비교 방법
- 엔티티를 수정하고 트랜잭션을 커밋하면 영속성 컨텍스트를 플러시하면서 UPDATE 쿼리를 실행한다.
- 이 때 버전을 사용하는 엔티티면 검색 조건에 엔티티의 버전 정보를 추가한다.
UPDATE BOARD
SET TITLE = ?,
VERSION = ? (버전 증가)
WHERE ID = ? AND VERSION = ? (버전 비교)
- 데이터베이스 버전과 엔티티 버전이 같으면 데이터를 수정하면서 버전을 하나 증가시킨다.
- 만약 데이터베이스 버전과 엔티티의 버전이 다르면
WHERE문에서VERSION값이 다르므로 수정할 대상이 없다.- 이 때는 JPA가 버전이 이미 증가한 것으로 판단해서 예외를 발생시킨다.
JPA 락 사용
-
락은 다음 위치에 적용할 수 있다.
-
EntityManager.lock(),EntityManager.find(),EntityManager.refresh()Board board = em.find(Board.class, id, LockModeType.OPTIMISTIC);Board board = em.find(Board.class, id); ... em.lock(board, LockModeType.OPTIMISTIC); -
Query.setLockMode() -
@NamedQuery
-
-
JPA가 제공하는 락 옵션은 다음과 같다.
| 락 모드 | LockModeType | 설명 |
|---|---|---|
| 낙관적 락 | OPTIMISTIC | 낙관적 락을 사용한다. |
| 낙관적 락 | OPTIMISTIC_FORCE_INCREMENT | 낙관적 락 + 버전 정보를 강제로 증가한다. |
| 비관적 락 | PESSIMISTIC_READ | 비관적 락, 읽기 락을 사용한다. |
| 비관적 락 | PESSIMISTIC_WRITE | 비관적 락, 쓰기 락을 사용한다. |
| 비관적 락 | PESSIMISTIC_FORCE_INCREMENT | 비관적 락 + 버전 정보를 강제로 증가한다. |
| 기타 | NONE | 락을 걸지 않는다. |
| 기타 | READ | OPTIMISTIC과 같다. |
| 기타 | WRITE | OPTIMISTIC_FORCE_INCREMENT와 같다. |
JPA 낙관적 락
-
JPA가 제공하는 낙관적 락은
@Version을 사용한다. -
낙관적 락에서 발생하는 예외는 다음과 같다.
- JPA 예외 :
OptimisticLockExcption - 하이버네이트 예외 :
StableObjectStateException - 스프링 예외 추상화 :
ObjectOptimisticLockingFailureException
- JPA 예외 :
NONE
- 락 옵션을 적용하지 않아도 엔티티에
@Version이 적용된 필드만 있으면 낙관적 락이 적용된다. - 용도 : 조회한 엔티티를 수정할 때 다른 트랜잭션에 의해 변경되지 않아야 한다.
- 동작 : 엔티티를 수정할 때 버전을 체크하면서 버전을 증가한다.
- 데이터베이스 버전 값이 엔티티 버전 값과 다르면 예외가 발생한다.
- 이점 : 두 번의 갱신 분실 문제를 예방한다.
OPTIMISTIC
- 용도 : 조회된 엔티티는 트랜잭션이 끝날 때까지 다른 트랜잭션에 의해 변경되지 않아야 한다.
- 즉, 조회 시점부터 트랜잭션이 끝날 때까지 조회한 엔티티가 변경되지 않음을 보장한다.
- 동작 : 트랜잭션을 커밋할 때 버전 정보를 조회해서(SELECT 쿼리 사용) 현재 엔티티의 버전과 같은지 검증한다.
- 같지 않으면 예외가 발생한다.
- 이점 : DIRTY READ와 NON-REPEATABLE READ를 예방한다.
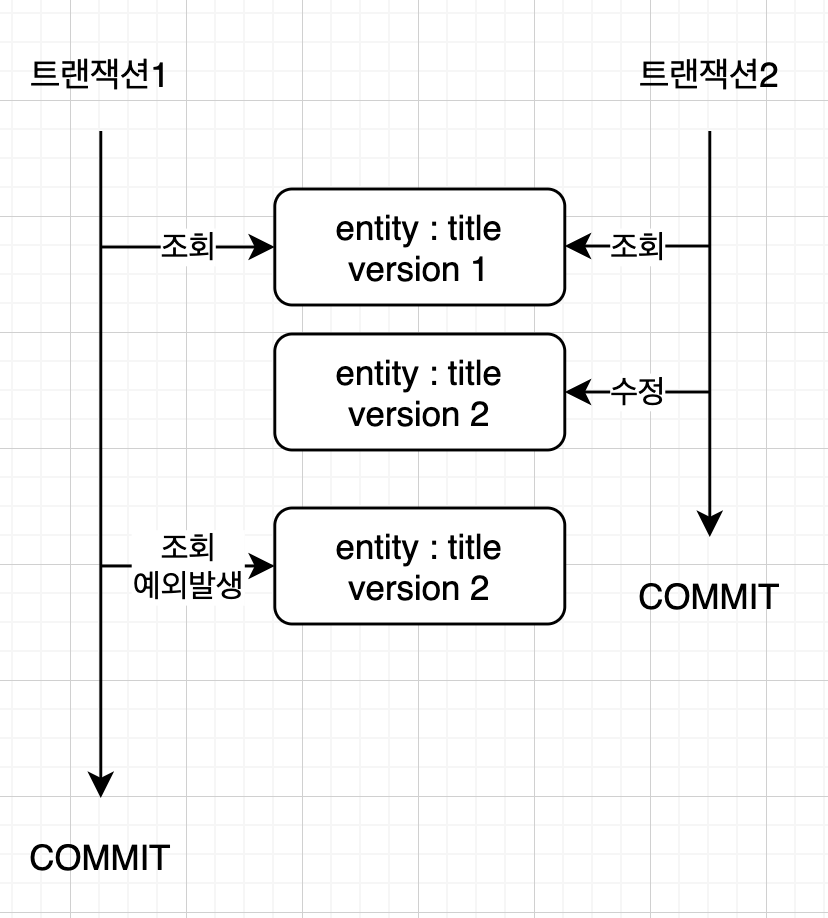
@Version만 사용하면 엔티티를 수정해야 버전 정보를 확인하지만OPTIMISTIC옵션을 사용하면 엔티티를 단순히 조회만 해도 버전을 확인한다.
OPTIMISTIC_FORCE_INCREMENT
- 용도 : 논리적인 단위의 엔티티 묶음을 관리할 수 있다.
- 예를 들어, 게시물-첨부파일의 일대다 양방향 연관관계에서 게시물 수정시에 단순히 첨부파일만 추가하면 게시물의 버전은 증가하지 않는다.
- 해당 게시물은 물리적으로는 변경되지 않았지만 논리적으로 변경되었다.
- 이 때 게시물의 버전도 강제로 증가하려면
OPTIMISTIC_FORCE_INCREMENT옵션을 사용한다.
- 예를 들어, 게시물-첨부파일의 일대다 양방향 연관관계에서 게시물 수정시에 단순히 첨부파일만 추가하면 게시물의 버전은 증가하지 않는다.
- 동작 : 엔티티를 수정하지 않아도 트랜잭션을 커밋할 때 UPDATE SQL을 사용해서 버전 정보를 강제로 증가시킨다.
- 이 때 데이터베이스 버전이 엔티티의 버전과 다르면 예외가 발생한다.
- 추가로 엔티티를 수정하면 또 다시 버전 UPDATE가 발생한다. 따라서 총 2번의 버전 증가가 나타날 수 있다.
- 이점 : 논리적인 단위의 엔티티 묶음을 버전 관리할 수 있다.
JPA 비관적 락
- JPA가 제공하는 비관적 락은 데이터베이스 트랜잭션 락에 의존하는 방법이다.
- SQL 쿼리에
select for update구문을 사용하면서 시작하고, 버전 정보는 사용하지 않는다. - 비관적 락은 다음과 같은 특징이 있다.
- 엔티티가 아닌 스칼라 타입을 조회할 때도 사용할 수 있다.
- 데이터를 수정하는 즉시 트랜잭션 충돌을 감지할 수 있다.
- 비관적 락에서 발생하는 예외는 다음과 같다.
- JPA 예외 :
PessimisticLockException - 스프링 예외 추상화 :
PessimisticLockingFailureException
- JPA 예외 :
PESSIMISTIC_WRITE
- 비관적 락이라 하면 일반적으로 이 옵션을 뜻한다.
- 용도 : 데이터베이스에 쓰기 락을 건다.
- 동작 : 데이터베이스
select for update를 사용해서 락을 건다. - 이점 : NON-REPEATABLE READ를 방지한다.
- 락이 걸린 row는 다른 트랜잭션이 수정할 수 없다.
PESSIMISTIC_READ
- 데이터를 반복 읽기만 하고 수정하지 않는 용도로 락을 걸 때 사용한다.
- MySQL :
lock in share mode
PESSIMISTIC_FORCE_INCREMENT
- 비관적 락 중 유일하게 버전 정보를 사용한다.
- 버전 정보를 강제로 증가시킨다.
- Oracle :
for update nowait - MySQL :
for update
비관적 락과 타임아웃
- 비관적 락을 사용하면 락을 획득할 때까지 트랜잭션이 대기한다.
- 락을 대기하는 타임아웃 시간을 줄 수 있는데, 타임아웃 시간이 지나면
LockTimeoutException이 발생한다.
Map<String, Object> properties = new HashMap<String, Object>();
properties.put("javax.persistence.lock.timeout", 10000);
Board board = em.find(Board.class, boardId, LockModeType.PESSIMISTIC_WRITE, properties);
2차 캐시
1차 캐시와 2차 캐시
- 네트워크를 통해 데이터베이스에 접근하는 시간 비용은 어플리케이션 서버에서 내부 메모리에 접근하는 시간 비용보다 수십만 배 이상 비싸다.
- 데이터베이스에서 조회한 데이터를 메모리에 캐시하면 어플리케이션 성능을 획기적으로 줄일 수 있다.
- 영속성 컨텍스트 내부에는 엔티티를 보관하는 저장소가 있는데, 이것을 1차 캐시라 한다.
- 일반적으로 웹 어플리케이션에서 트랜잭션을 시작하고 종료할 때까지만 1차 캐시가 유효하다.
- 따라서 어플리케이션 전체로 보면 데이터베이스 접근 횟수를 획기적으로 줄이지는 못한다.
- 대부분의 JPA 구현체들은 어플리케이션 범위의 캐시를 지원하는데 이것을 공유 캐시 또는 2차 캐시라 한다.
1차 캐시
- 1차 캐시는 끄고 켤 수 있는 옵션이 아니다.
- 영속성 컨텍스트 자체가 사실상 1차 캐시다.
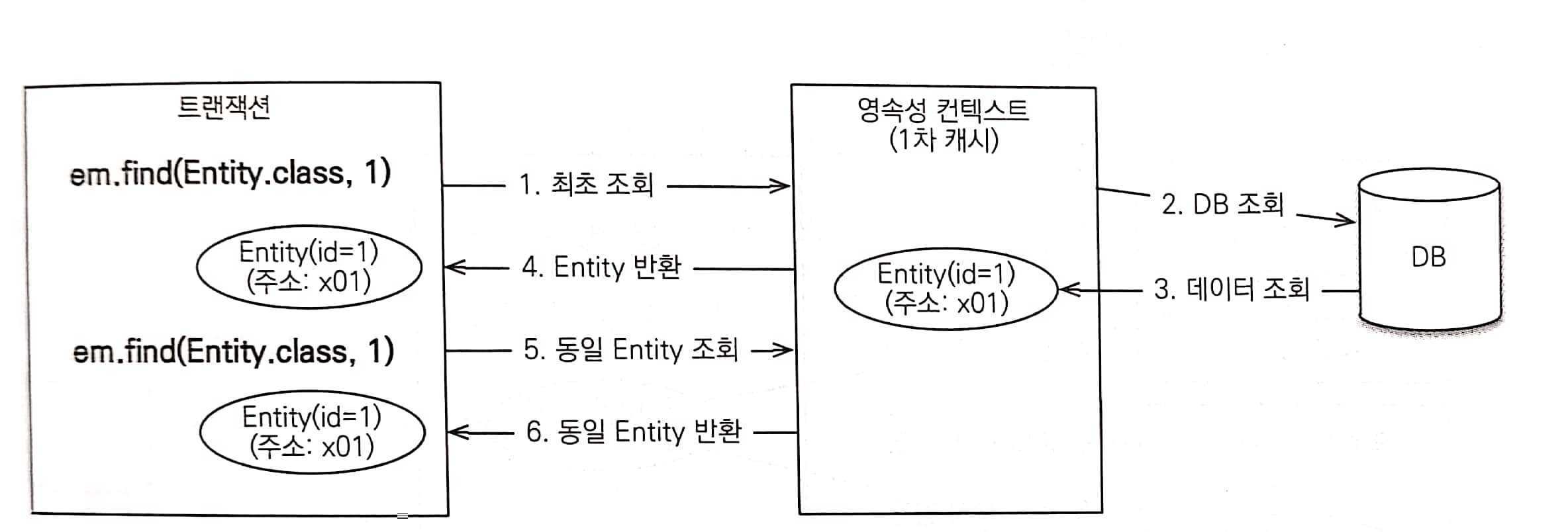
- 최초 조회할 때는 1차 캐시에 엔티티가 없다.
- 데이터베이스에서 엔티티를 조회한다.
- 1차 캐시에 조회한 엔티티를 보관한다.
- 1차 캐시에 보관한 결과를 반환한다.
- 이후 같은 엔티티를 조회하면 1차 캐시에 같은 엔티티가 있으므로 데이터베이스를 조회하지 않고 1차 캐시의 엔티티를 그대로 반환한다.
- 1차 캐시는 같은 엔티티가 있으면 해당 엔티티를 그대로 반환한다. 따라서 1차 캐시는 객체 동일성(
a==b)을 보장한다.
2차 캐시
- 어플리케이션에서 공유하는 캐시를 2차 캐시(second level cache,
L2 cache)라 부른다.- 어플리케이션을 종료할 때까지 캐시가 유지된다.
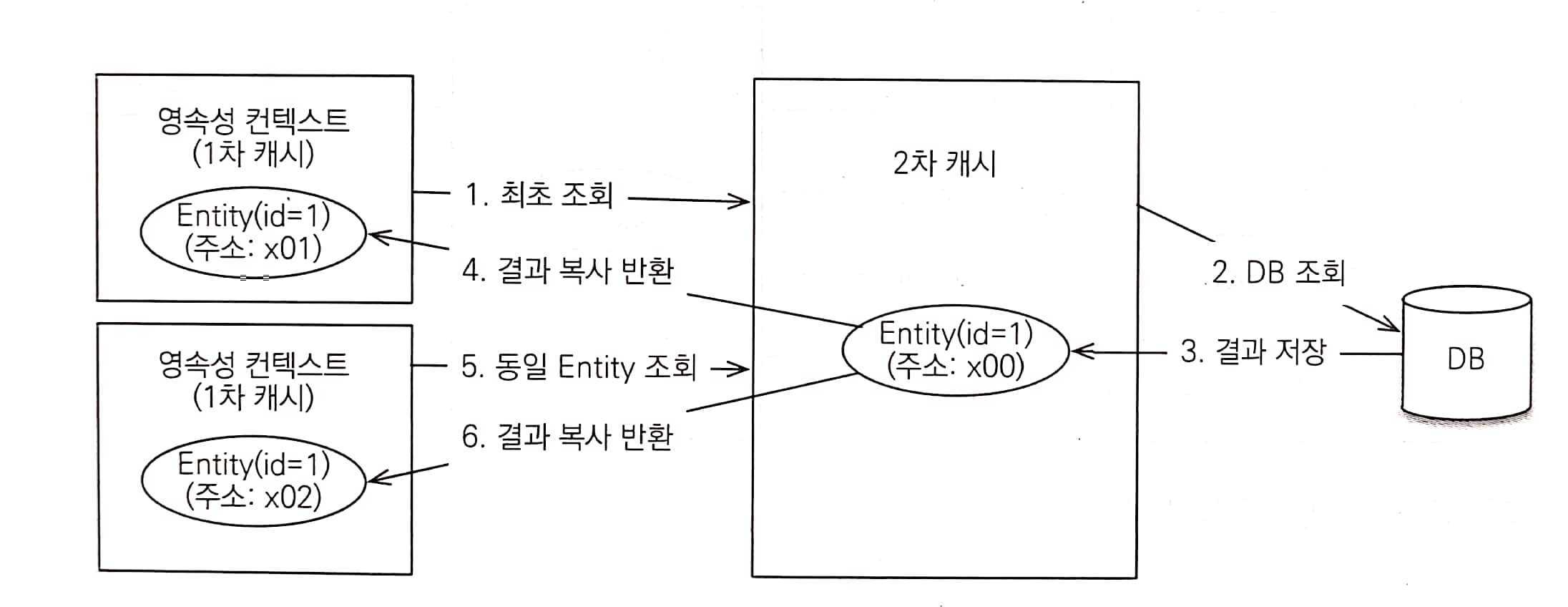
- 영속성 컨텍스트는 엔티티가 필요하면 2차 캐시를 조회한다.
- 2차 캐시에 엔티티가 없으면 데이터베이스를 조회한다.
- 데이터베이스 조회 결과를 2차 캐시에 보관한다.
- 2차 캐시는 자신이 보관하고 있는 엔티티를 복사해서 반환한다.
- 2차 캐시에 저장되어 있는 엔티티를 조회하면 복사본을 만들어 반환한다.
- 2차 캐시는 동시성을 극대화하기 위해 캐시한 객체를 직접 반환하지 않고 복사본을 만들어서 반환한다.
- 2차 캐시는 데이터베이스 기본 키를 기준으로 캐시하지만 영속성 컨텍스트가 다르면 객체 동일성을 보장하지 않는다.
JPA 2차 캐시 기능
캐시 모드 설정
- 2차 캐시를 사용하려면 엔티티에
@Cacheable어노테이션을 사용하면 된다.
@Cacheable
@Entity
public class Member {
...
}
- 캐시 모드는
SharedCacheMode에 정의되어 있다.- 보통
ENABLE_SELECTIVE를 사용한다.
- 보통
| 캐시 모드 | 설명 |
|---|---|
| ALL | 모든 엔티티를 캐시한다. |
| NONE | 캐시를 사용하지 않는다. |
| ENABLE_SELECTIVE | Cacheable(true) 로 설정된 엔티티만 캐시를 적용한다. |
| DISABLE_SELECTIVE | 모든 엔티티를 캐시하는데 @Cacheable(false) 로 설정된 엔티티는 캐시하지 않는다. |
| UNSPECIFIED | JPA 구현체가 정의한 설정을 따른다. |
캐시 조회, 저장 방식 설정
- 캐시를 무시하고 데이터베이스를 직접 조회하거나 캐시를 갱신하려면 캐시 조회 모드와 캐시 보관 모드를 사용하면 된다.
- 캐시 조회 모드
- 프로퍼티 이름 :
javax.persistence.cache.retrieveMode - 옵션 :
CacheRetrieveMode
- 프로퍼티 이름 :
- 캐시 보관 모드
- 프로퍼티 이름 :
javax.persistence.cache.storeMode - 옵션 :
CacheStoreMode
- 프로퍼티 이름 :
- 캐시 조회 모드
public enum CacheRetrieveMode {
USE, // 캐시에서 조회한다. (기본값)
BYPASS // 캐시를 무시하고 데이터베이스에 직접 접근한다.
}
public enum CacheStoreMode {
USE, // 조회한 데이터를 캐시에 저장한다.
BYPASS, // 캐시에 저장하지 않는다.
REFRESH // USE 전략에 추가로 데이터베이스에서 조회한 엔티티를 최신 상태로 다시 캐시한다.
}
USE: 조회한 데이터가 이미 캐시에 있으면 캐시 데이터를 최신 상태로 갱신하지는 않는다.- 트랜잭션을 커밋하면 등록 수정한 엔티티도 캐시에 저장한다.
캐시 모드 설정
- 엔티티 매니저 단위로 설정
em.setProperty("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS);
em.setProperty("javax.persistence.cache.storeMode", CacheStoreMode.BYPASS);
- 쿼리 단위로 설정
Map<String, Object> param = new HashMap<String, Object>();
param.put("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS);
param.put("javax.persistence.cache.storeMode", CacheStoreMode.BYPASS);
em.find(Member.class, id, param);
em.createQuery("select m from Member m where m.id = :id", Member.class)
.setParameter("id", id)
.setHint("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS)
.setHint("javax.persistence.cache.storeMode", CacheStoreMode.BYPASS)
.getSingleResult();
JPA 캐시 관리 API
- JPA는 캐시를 관리하기 위한
Cache인터페이스를 제공한다.
Cache cache = entityManagerFactory.getCache();
boolean contains = cache.contains(Member.class, member.getId());
하이버네이트와 EHCACHE 적용
- 하이버네이트가 지원하는 캐시는 크게 3가지가 있다.
- 엔티티 캐시 : 엔티티 단위로 캐시한다. 식별자로 엔티티를 조회하거나 컬렉션이 아닌 연관된 엔티티를 로딩할 때 사용한다.
- 컬렉션 캐시 : 엔티티와 연관된 컬렉션을 캐시한다. 컬렉션이 엔티티를 담고 있으면 식별자 값만 캐시한다.
- 쿼리 캐시 : 쿼리와 파라미터 정보를 키로 사용해서 캐시한다. 결과가 엔티티면 식별자 값만 캐시한다.
환경 설정
-
하이버네이트에서 EHCACHE를 사용하려면
hibernate-ehcache라이브러리를 추가해야 한다. -
다음으로
application.properties에 캐시 사용 정보를 설정해야 한다.spring.jpa.properties.hibernate.cache.use_second_level_cache=true spring.jpa.properties.hibernate.cache.use_query_cache=true spring.jpa.properties.hibernate.cache.region.factory_class=org.hibernate.cache.ehcache.EhCacheRegionFactoryhibernate.cache.use_second_level_cache: 2차 캐시를 활성화 한다.- 엔티티 캐시와 컬렉션 캐시를 사용할 수 있다.
hibernate.cache.use_query_cache: 쿼리 캐시를 활성화 한다.hibernate.cache.region.factory_class: 2차 캐시를 처리할 클래스를 지정한다.
엔티티 캐시와 컬렉션 캐시
@Cacheable
@Cache(usage=CacheConcurrencyStrategy.READ_WRITE)
@Entity
public class ParentMember {
@Id
@GeneratedValue
private Long id;
private String name;
@Cache(usage=CacheConcurrencyStrategy.READ_WRITE)
@OneToMany(mappedBy="parentMember", cascade=CascadeType.ALL)
private List<ChildMember> childMembers = new ArrayList<ChildMember>();
...
}
@Cacheable: 엔티티를 캐시하기 위한 어노테이션@Cache: 더 세밀한 설정이나 컬렉션 캐시를 적용하기 위한 어노테이션usage:CacheConcurrencyStrategy를 사용해서 캐시 동시성 전략을 설정한다.region: 캐시 지역 설정include: 연관 객체를 캐시에 포함할지 선택한다.all,non-lazy옵션을 선택할 수 있다.
캐시 동시성 전략
| 속성 | 설명 |
|---|---|
| NONE | 캐시를 설정하지 않는다. |
| READ_ONLY | 읽기 전용으로 설정한다. 등록, 삭제는 가능하지만 수정은 불가능하다. 읽기 전용인 불변 객체는 수정되지 않으므로 2차 캐시 조회시에 객체를 복사하지 않고 원본 객체를 반환한다. |
| NONSTRICT_READ_WRITE | 엄격하지 않은 읽고 쓰기 전략이다. 데이터를 수정하면 캐시 데이터를 무효화한다. |
| READ_WRITE | 읽고 쓰기가 가능하고 READ COMMITED 정도의 격리 수준을 보장한다. 데이터를 수정하면 캐시 데이터도 같이 수정한다. |
| TRANSACTIONAL | 설정에 따라 REPEATABLE READ 정도의 격리 수준을 보장받을 수 있다. |
쿼리 캐시
- 쿼리 캐시는 쿼리와 파라미터 정보를 키로 사용해서 쿼리 결과를 캐시하는 방법이다.
- 캐시를 적용하려는 쿼리마다 힌트를 설정해주면 된다.
em.createQuery("select i from Item i", Item.class)
.setHint("org.hibernate.cacheable", true)
.getResultList();
- Named 쿼리에도 캐시를 적용할 수 있다.
@Entity
@NamedQuery(hints = @QueryHint(name="org.hibernate.cacheable", value=true),
name="Member.findByUsername",
query = "select m.address from Member m where m.name = :username")
public class Member {
...
}
쿼리 캐시 영역
StandardQueryCache: 쿼리 캐시를 저장하는 영역- 쿼리, 쿼리 결과 집합, 쿼리를 실행한 시점의 timestamp를 보관한다.
UpdateTimestampCache: 쿼리 캐시가 유효한지 확인하기 위해 쿼리 대상 테이블의 가장 최근 변경 시간을 저장하는 영역- 테이블 명과 해당 테이블의 최근 변경된 timestamp를 보관한다.
- 쿼리 캐시는 캐시한 데이터 집합을 최신 데이터로 유지하려고 쿼리 캐시를 실행하는 시간과 쿼리 캐시가 사용하는 테이블들이 가장 최근에 변경된 시간을 비교한다.
UpdateTimestampCache캐시 영역에서 조회해서 테이블의 타임스탬프를 확인한다.StandardQueryCache캐시 영역의 타임스탬프가 더 오래되었으면 캐시가 유효하지 않은 것으로 보고 데이터베이스에서 데이터를 조회해서 다시 캐시한다.
쿼리 캐시와 컬렉션 캐시의 주의점
- 쿼리 캐시와 컬렉션 캐시는 결과 집합의 식별자 값만 캐시한다.
- 이 식별자 값을 하나씩 엔티티 캐시에서 조회해서 실제 엔티티를 찾는다.
- 쿼리 캐시나 컬렉션 캐시만 적용하고 대상 엔티티에 엔티티 캐시를 적용하지 않으면 성능상 심각한 문제가 발생할 수 있다.
- 쿼리 캐시나 컬렉션 캐시를 사용하면 결과 대상 엔티티에는 꼭 엔티티 캐시를 적용해야 한다.